
TL;DR
- Ruby scraping with
Nokogiri+HTTParty; quick Bundler setup and simple scaffold. - Walkthrough: fetch HTML, parse with
Nokogiri, select elements, build an array of job records. - Add pagination: derive pages from per-page count and total, loop through and aggregate results.
- Takeaway: a small
Nokogiriscript scales to multi-page crawls; starter code included.
Web Scraping can be done via different programming languages. Ruby is considered one of the best programming languages for web scraping.
In this quick guide, we will learn how you can scrape pages using this programming language.
Here is the URL for that web page which we will be going to scrape with the help of Ruby in this tutorial.
Ruby Web Scraping
Ruby Web Scraping can be used to extract information such as product details, prices, contact information, and more.
Scraping data from websites can be a tedious and time-consuming task, especially if the website is not well structured. This is where Ruby comes in handy. Ruby is a powerful programming language that makes it easy to process and extract data from websites.
With Ruby, you can use the Nokogiri and Open-URI gems to easily extract data from websites. Nokogiri is a Ruby gem that makes it easy to parse and search HTML documents. Open-URI is a Ruby gem that allows you to open and read files from the web.
In this article, we will learn how to scrape websites using the Ruby programming language. We will use the Nokogiri and Open-URI gems to make our life easier. We will also look at how to scrape paginated data.
Ruby Scraper Library
Setup
Our setup is pretty simple. Just type the below commands in cmd.
mkdir scraper
cd scraper
touch GemFile
touch scraper.rb
Now, you can open this scraper folder in any of your favorite code editors. I will use Atom. Inside our scraper folder, we have our GemFile and a scraper file.
For our scaper, we are going to use a couple of gems. So, the first thing I want to do is jump into the gem file we just created and I am going to add a couple of things. We are going to add three gems one is an HTTP party, another one is Nokogiri and the last one is Byebug.
source "https://rubygems.org"
gem "httparty"
gem "nokogiri"
gem "byebug"
Now, go back to your cmd and install all the gems using
bundle install
After this everything is set and a file name gemfile.lock has been created in our working folder. Or setup is complete.
Preparing the Food
Now we are going to start writing our scraper in scraper.rb file. Before we start writing our scraper I am going to require the dependencies that we just added to our gem file. So, we’ll add nokogiri, byebug, and httparty.
require 'nokogiri'
require 'httparty'
require 'byebug'
I am going to create a new method and call it scraper and this is where all of our scraper functionality is going to live.
def scraper
url = "https://blockwork.cc/"
unparsed_page = Httparty.get(url)
parse_page = Nokogiri::HTML(unparsed_page)
byebug
end
scraper
We have declared a variable inside the function by the name URL and then to make an HTTP GET request to this URL we are going to use httparty.
After HTTP call, we’ll get raw HTML source code from that web page. So, what we can do next is we can bring Nokogiri and we can parse that page.
So let’s create another variable called parse_page. Nokogiri will provide us with a format from which we can start to extract data out of the raw HTML. Then we used Byebug. It will set up a debugger that lets us interact with some of these variables. Once we have added that we can jump back to our cmd.
ruby scraper.rb
parse_page #on hitting byebug
On writing “parsed_page” after hitting byebug we’ll get…

Here, we can use nokogiri to interact with this data. So, this is where things get pretty cool. Using Nokogiri we can target various items on the page like classes, IDs, etc. We’ll inspect the job page and we’ll find the class associated with each job block.
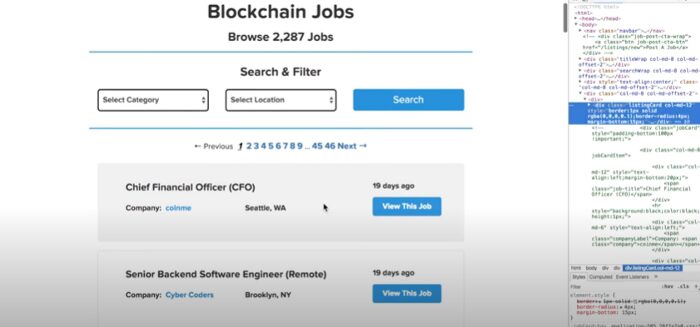
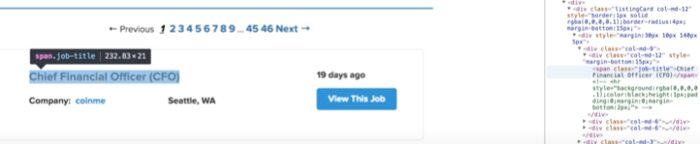
On inspection, we see that every job has a class “listingCard”.
In cmd type
jobCards = parsed_page.css(‘div.listingCard’)

#Coming back to scraper.rb
def scraper
url = "https://blockwork.cc/"
unparsed_page = Httparty.get(url)
parse_page = Nokogiri::HTML(unparsed_page)
jobs = Array.new
job_listings = parsed_page.css("div.lisingCard")
job_listings.each do [job_listing]
job = {
title:job_listing.css('span.job-title'),
company: job_listing.css('span.company'),
location:job_listing.css('span.location'),
url:"https://blockwork.cc" + job_listing.css('a')[0].attributes['href'].value
}
jobs == job
end
byebug
end
scraper
We have created a variable job_listings which contains all the top 50 job postings on the page. And then we want to pass that data into an array. We have created a job object which will hold all the individual company details.
Now, we can iterate over 50 jobs on a page and we should be able to extract the data that we are trying to target out of each of those jobs. A jobs array has been declared to store all 50 job listings one by one. Now, we can run our script on cmd to check all 50 listings.
ruby scraper.rb
jobs #After hitting the byebug

We have managed to scrape the first page but what if we want to scrape all the pages?
Scraping Every Page
We have to make our scraper a little more intelligent. We are going to make a few tweaks to our web scraper. Here we will take pagination into account and we’ll scrape all the listings on this site instead of just 50 per page.
There are a couple of things we want to know to make this work. The first is just how many listings are getting served on each page. So, we already know that it’s 50 listings per page. The other thing we want to figure out is the total number of listings on the site. We already know that we have 2287 listings on the site.
#Coming back to scraper.rb
def scraper
url = "https://blockwork.cc/"
unparsed_page = Httparty.get(url)
parse_page = Nokogiri::HTML(unparsed_page)
jobs = Array.new
job_listings = parsed_page.css("div.lisingCard")
page = 1
per_page = job_listings.count #50
total = parsed_page.css('div.job-count').text.split(' ')[1].gsub(',','').to_i #2287
last_page = (total.to_f / per_page.to_f).round
while page <= last_page
pagination_url = "https://blockwork.cc/listings?page=#{page}"
pagination_unparsed_page = Httparty.get(pagination_url)
pagination_parse_page = Nokogiri::HTML(pagination_unparsed_page)
pagination_job_listings = pagination_parsed_page.css("div.lisingCard")
pagination_job_listings.each do [job_listing]
job = {
title:job_listing.css('span.job-title'),
company: job_listing.css('span.company'),
location:job_listing.css('span.location'),
url:"https://blockwork.cc" + job_listing.css('a')[0].attributes['href'].value
}
jobs << job
end
page += 1
end
byebug
end
scraper
per_page will calculate the job listings on a page and the total will calculate the total number of job postings. We should avoid making it hardcoded. last_page will determine the last page number. We have declared a while loop which will stop when the page will become equal to the last_page. pagination_url will provide a new URL for every page value. Then the same logic will be followed as what we used while scraping the first page. Array jobs will contain all the jobs present on the website.
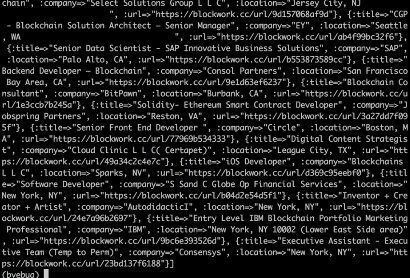
So, just like that, we can build a simple and powerful web scraper using Ruby and Nokogiri.
Key Takeaways:
Ruby can be used for web scraping with libraries like
Nokogirifor parsing HTML and XML.open-uriorHTTPartyhelps send HTTP requests and fetch web page content.Nokogiri supports both CSS selectors and XPath for precise data extraction.
Handling pagination, headers, and user agents is important to avoid basic blocking.
For large-scale or protected websites, proxy management and anti-bot handling become necessary.
Conclusion
In this article, we understood how we can scrape data using Ruby and Nokogiri. Once you start playing with it you can do a lot with Ruby. Ruby on Rails makes it easy to modify the existing code or add new features. Ruby is a concise language when combined with 3rd party libraries, which allows you to develop features incredibly fast. It is one of the most productive programming languages around.
Feel free to comment and ask me anything. You can follow me on Twitter and Medium. Thanks for reading and please hit the like button!
Frequently Asked Questions
Is Ruby a dying language?
No, Ruby is not a dying language. While its popularity has decreased compared to some newer languages, it remains a viable choice due to its mature ecosystem, readability, and the ongoing development of the Ruby on Rails framework.
Is Ruby better then Python?
It’s not accurate to say one language is definitively better than the other, as Ruby and Python both have their strengths and use cases. However, if you want to learn web scraping Python, we have a dedicated blog made here.
Additional Resources
And there’s the list! At this point, you should feel comfortable writing your first web scraper with Ruby to gather data from any website. Here are a few additional resources that you may find helpful during your web scraping journey:


