
TL;DR
- Intro to regex for scraping / cleaning; Python
rebasics. - Walkthrough: download Books to Scrape HTML with
requestsand use two regex patterns to extract book titles and prices; full runnable code. - Produces a list of
{Title, Price}records. - Ends with a Scrapingdog trial CTA (1k free credits).
With all the data that you collect, much of it is not usable. And cleaning it can be a hectic task.
Regex can be used to clean this data efficiently and in this blog, you will learn how to do it.
What you will learn from this article?
- How regular expressions can be used in Python?
- How to create patterns.
I am assuming that you have already installed Python 3.x on your computer. If not then please install it from here.
What is Regular Expression?
Regular expression or regex is like a sequence of characters that forms a search pattern that can be used for matching strings. It is a very powerful tool that can be used for text processing, data extraction, etc. It is supported by almost every language including Python, JavaScript, Java, etc. It has great community support which makes searching and matching using Regex super easy.
There are five types of Regular Expressions:
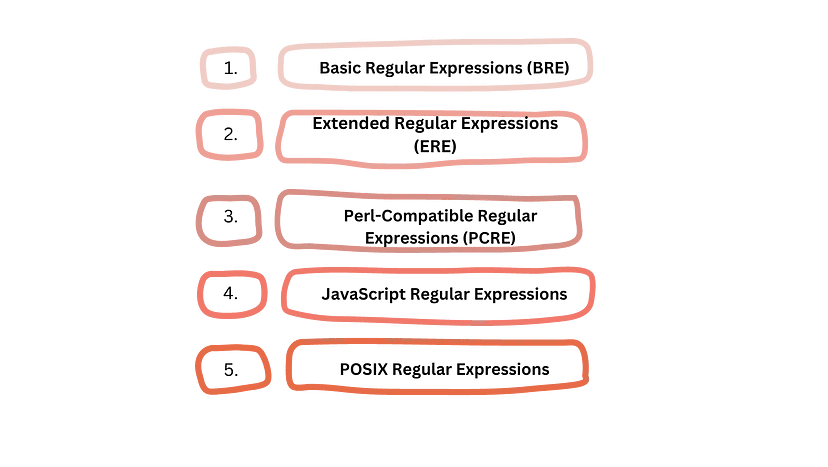
Here is how regex can be used for data extraction
- A sequence of characters is declared to match a pattern in the string.
- In the above sequence of characters, metacharacters like dot
.or asterisk*are also often used. Here the dot (.) metacharacter matches any single character, and the asterisk (*) metacharacter represents zero or more occurrences of the preceding character or pattern. - Quantifiers are also used while making the pattern. For example, the plus (+) quantifier indicates one or more occurrences of the preceding character or pattern, while the question mark (?) quantifier indicates zero or one occurrence.
- Character classes are used in the pattern to match the exact position of the character in the text. For example, the square brackets ([]) can be used to define a character class, such as [a-z] which matches any lowercase letter.
- Once this pattern is ready you can apply it to the HTML code you have downloaded from a website while scraping it.
- After applying the pattern you will get a
listof matching strings in Python.
Example
Let’s say we have this text.
text = "I have a cat and a catcher. The cat is cute."
Our task is to search for all occurrences of the word “cat” in the above-given text string.
We are going to execute this task using the re library of Python.
In this case, the pattern will be r’\bcat\b’. Let me explain the step-by-step breakdown of this pattern.
\b: This is a word boundary metacharacter, which matches the position between a word character (e.g., a letter or a digit) and a non-word character (e.g., a space or a punctuation mark). It ensures that we match the whole word “cat” and not part of a larger word that contains “cat”.cat: This is the literal string “cat” that we want to match in the text.\b: Another word boundary metacharacter, which ensures that we match the complete word “cat”. If you want to learn more about word boundaries then read this article.
Python Code
import re
text = "I have a cat and a catcher. The cat is cute."
pattern = r'\bcat\b'
matches = re.findall(pattern, text)
print(type(matches))
In this example, we used the re.findall() function from the re module in Python to find all matches of the regular expression pattern \bcat\b in the text string. The function returned a list with the matched word “cat” as the result.
The output will look like this.
['cat', 'cat']
This is just a simple example for beginners. Of course, regular expression becomes a little complex with complex HTML code. Now, let’s test our skill in parsing HTML using regex with a more complex example.
Parsing HTML with Regex
We are going to scrape a website in this section. We are going to download HTML code from the target website and then parse data out of it completely using Regex.
For the sake of this tutorial, I am going to use this website. We will use two third-party libraries of Python to execute this task.
What are we going to scrape?
It is always better to decide in advance what exactly we want to scrape from the website.
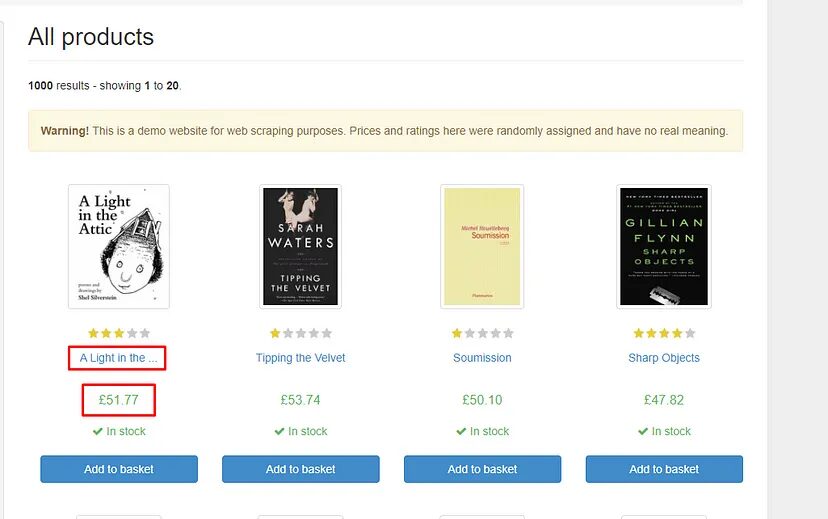
We are going to scrape two things from this page.
- Title of the book
- Price of the book
Let’s Download the data
I will make a GET request to the target website in order to download all the HTML data from the website. For that, I will be using the requests library.
import requests
import re
l=[]
o={}
# Send a GET request to the website
target_url = 'http://books.toscrape.com/'
response = requests.get(target_url)
# Extract the HTML content from the response
html_content = response.text
Here is what we have done in the above code.
- We first downloaded both the libraries requests and re.
- Then empty
list landobject owere declared. - Then the target URL was declared.
- HTTP GET request was made using the
requestslibrary. - All the HTML data is stored inside the
html_contentvariable.
Let’s parse the data with Regex
Now, we have to design a pattern through which we can extract the title and the price of the book from the HTML content. First, let’s focus on the title of the book.
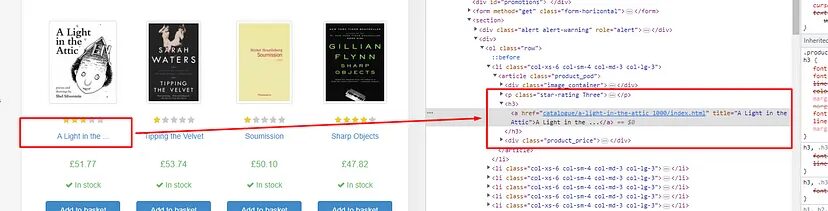
The title is stored inside the h3 tag. Then inside there is a a tag which holds the title. So, the title pattern should look like this.
title_pattern = r'<h3><a.*?>(.*?)<\/a><\/h3>'
I know you might be wondering how I created this pattern, right? Let me explain to you this pattern by breaking it down.
<h3>: This is a literal string that matches the opening<h3>tag in the HTML content.<a.*?>: This part of the pattern matches the<a>tag with any additional attributes that might be present in between the opening<a>tag and the closing>. The.*?is a non-greedy quantifier that matches zero or more characters in a non-greedy (minimal) way, meaning it will match as few characters as possible.(.*?): This part of the pattern uses parentheses to capture the text within the<a>tags. The.*?inside the parentheses is a non-greedy quantifier that captures any characters (except for newline) in a non-greedy (minimal) way.<\/a>: This is a literal string that matches the closing</a>tag in the HTML content.<\/h3>: This is a literal string that matches the closing</h3>tag in the HTML content.
So, the title_pattern is designed to match the entire HTML element for the book title, including the opening and closing <h3> tags, the <a> tag with any attributes, and the text within the <a> tags, which represent the book title. The captured text within the parentheses (.*?) is then used to extract the actual title of the book using the re.findall() function in Python.
Now, let’s shift our focus to the price of the book.

The price is stored inside the p tag with class price_color. So, we have to create a pattern that starts with <p class=”price_color”> and ends with </p>.
price_pattern = r'<p class="price_color">(.*?)<\/p>'
This one is pretty straightforward compared to the other one. But let me again break it down for you.
<p class="price_color">: This is a literal string that matches the opening<p>tag with the attributeclass="price_color", which represents the HTML element that contains the book price.(.*?): This part of the pattern uses parentheses to capture the text within the<p>tags. The.*?inside the parentheses is a non-greedy quantifier that captures any characters (except for newline) in a non-greedy (minimal) way.<\/p>: This is a literal string that matches the closing</p>tag in the HTML content.
So, the price_pattern is designed to match the entire HTML element for the book price, including the opening <p> tag with the class="price_color" attribute, the text within the <p> tags, which represent the book price, and the closing </p> tag. The captured text within the parentheses (.*?) is then used to extract the actual price of the book using the re.findall() function in Python.
import requests
import re
l=[]
o={}
# Send a GET request to the website
target_url = 'http://books.toscrape.com/'
response = requests.get(target_url)
# Extract the HTML content from the response
html_content = response.text
# Define regular expression patterns for title and price
title_pattern = r'<h3><a.*?>(.*?)<\/a><\/h3>'
price_pattern = r'<p class="price_color">(.*?)<\/p>'
# Find all matches of title and price patterns in the HTML content
titles = re.findall(title_pattern, html_content)
prices = re.findall(price_pattern, html_content)
Since titles and price variables are lists, we have to run a for loop to extract the corresponding titles and prices and store them inside a list l.
for i in range(len(titles)):
o["Title"]=titles[i]
o["Price"]=prices[i]
l.append(o)
o={}
print(l)
This way we will get all the prices and titles of all the books present on the page.
Complete Code
You can scrape many more things like ratings, product URLs, etc using regex. But for the current scenario, the code will look like this.
import requests
import re
l=[]
o={}
# Send a GET request to the website
target_url = 'http://books.toscrape.com/'
response = requests.get(target_url)
# Extract the HTML content from the response
html_content = response.text
# Define regular expression patterns for title and price
title_pattern = r'<h3><a.*?>(.*?)<\/a><\/h3>'
price_pattern = r'<p class="price_color">(.*?)<\/p>'
# Find all matches of title and price patterns in the HTML content
titles = re.findall(title_pattern, html_content)
prices = re.findall(price_pattern, html_content)
for i in range(len(titles)):
o["Title"]=titles[i]
o["Price"]=prices[i]
l.append(o)
o={}
print(l)
Key Takeaways:
Using regex to parse HTML is possible but generally not recommended for complex documents.
HTML structure is nested and unpredictable, which makes regex unreliable for large-scale parsing.
Regex may work for very simple and well-structured extraction tasks.
Dedicated parsers like BeautifulSoup or lxml handle HTML structure more accurately.
For maintainable and scalable scraping, structured parsing libraries are preferred over regex.
Conclusion
In this guide, we learned how you can parse HTML with Regex. For newcomers, regular expressions may initially seem daunting, but with consistent practice, their power and flexibility become unmistakable.
Regular expressions stand as a potent tool, especially when dealing with multifaceted data structures. Our previous article on web scraping Amazon data & pricing using Python showcased the use of regex in extracting product images, offering further insights into the versatility of this method. For a deeper dive and more real-world examples, I recommend giving it a read.
I hope you like this little tutorial of parsing HTML with Regex and if you do then please do not forget to share it with your friends and on your social media.


